Streaming#
hvPlot supports streamz DataFrame and Series objects, automatically generating streaming plots in a Jupyter notebook or deployed as a Bokeh Server app.
All hvPlot methods on streamz objects return HoloViews DynamicMap objects that update the plot whenever streamz triggers an event. For more information on DynamicMap and HoloViews dynamic plotting support, see the HoloViews User Guide; here we will focus on using the simple, high-level hvPlot API rather than on the details of how events and data flow behind the scenes.
All plots generated by the streamz plotting interface dynamically stream data from Python into the web browser. The web version for this page includes screen captures of the streaming visualizations, not live streaming data.
As for any of the data backends, we start by patching the streamz library with the plotting API:
import hvplot.streamz # noqa
Basic plotting#
Throughout this section we will be using the Random object from streamz, which provides an easy way of generating a DataFrame of random streaming data but which could be substituted with any streamz DataFrame or Series driven by a live, external data source instead. To stop the Random stream you can call df.stop() at any point.
from streamz.dataframe import Random
df = Random(interval='200ms', freq='50ms')
The plot method on Series and DataFrame is a simple wrapper around a line plot, which will plot all columns:
df.hvplot()
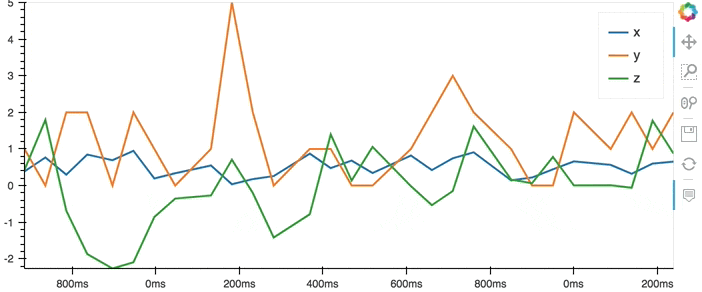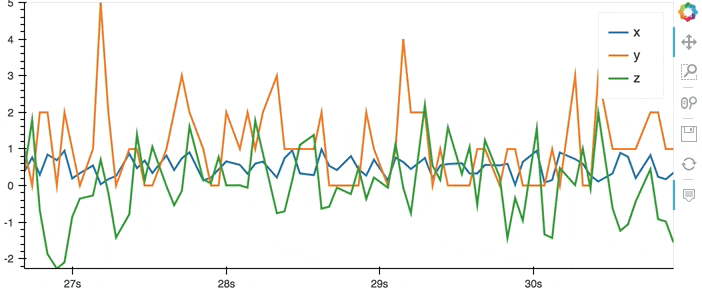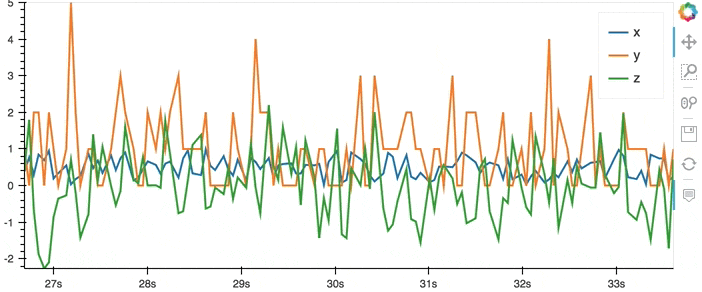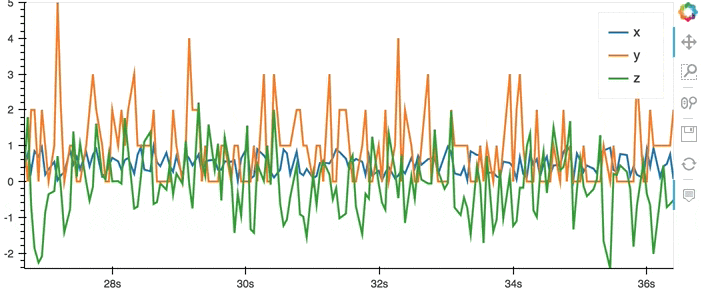
The plot method can also be called on a Series, plotting a specific column:
df.z.cumsum().hvplot()
Actually, all the functionality described in the Plotting user guide should work just the same as it does for a regular (non-streaming) dask or pandas DataFrame or Series, but will now update as new data appears.
Controlling the backlog#
The main difference when using a streaming DataFrame is that a only a certain amount of data will be buffered and displayed. The number of rows of data that will be buffered can be controlled by the backlog parameter. Here, let’s buffer and display 10 rows of our streaming DataFrame as a table:
df.hvplot.table(width=400, backlog=10)
This of course only has an effect when we are directly streaming data point by point. When we have an aggregate DataFrame, the plot will continuously accumulate updates:
df.groupby('y').sum().hvplot.bar(x='y')
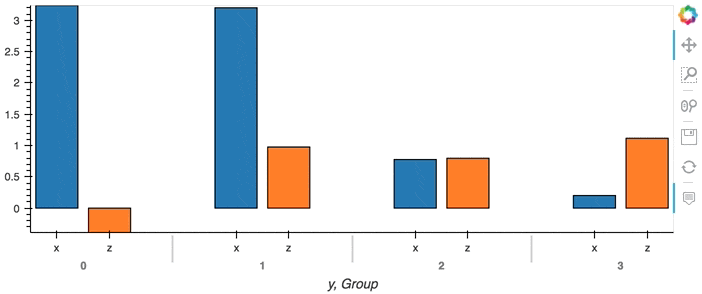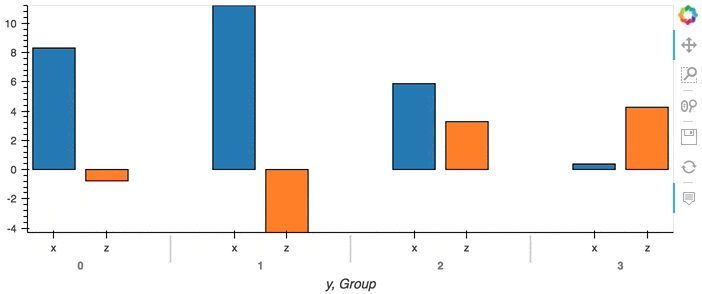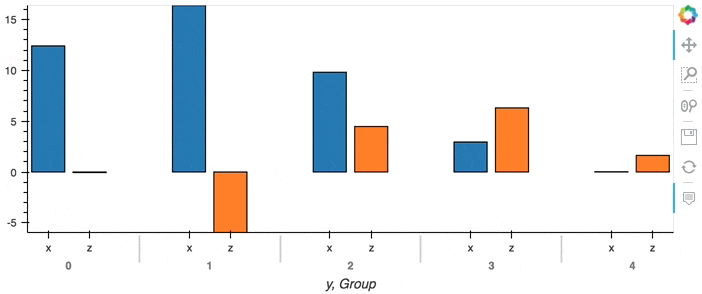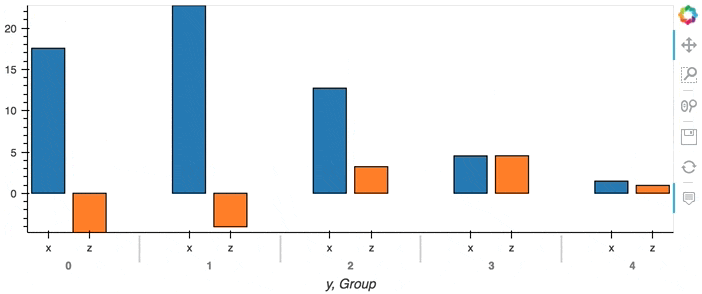
Composing Plots#
hvPlot is a convenient API for generating HoloViews objects. One of the core strengths of HoloViews objects is the ease with which they can be composed, which works with streaming plots just as with static ones. Individual plots can be composed using the * and + operators, which overlay and compose plots into layouts respectively. For more information on composing objects see the HoloViews User Guide.
By using these operators we can combine multiple plots into composite Overlay and Layout objects, and lay them out in two columns using the Layout.cols method:
(df.hvplot.line(width=400, backlog=100) * df.hvplot.scatter(width=400, backlog=100) +
df.groupby('y').sum().hvplot.bar('y', 'x', width=400) +
df.hvplot.box(width=400) + df.x.hvplot.kde(width=400, shared_axes=False)).cols(2)
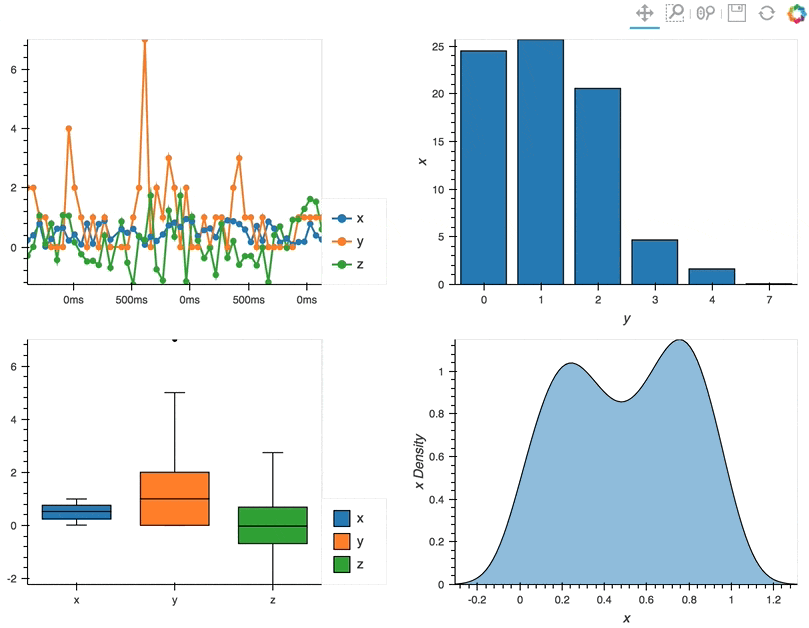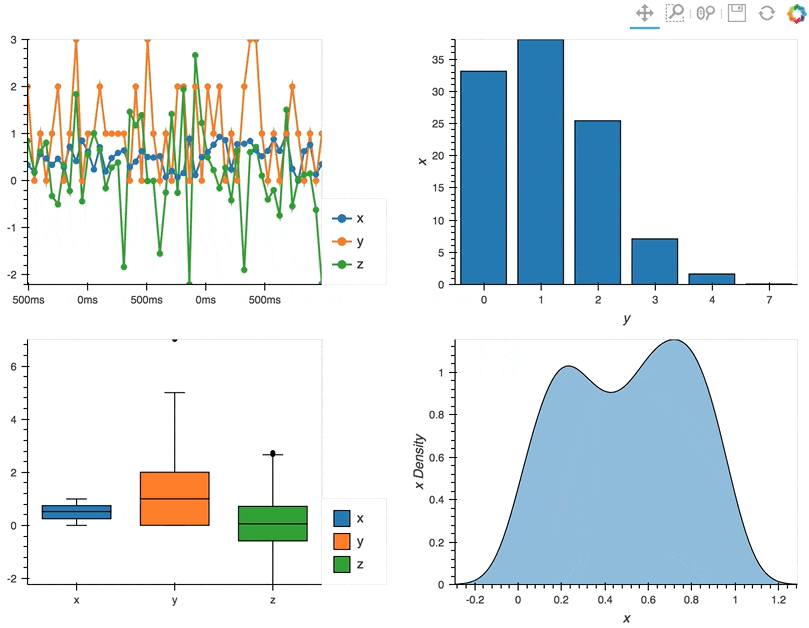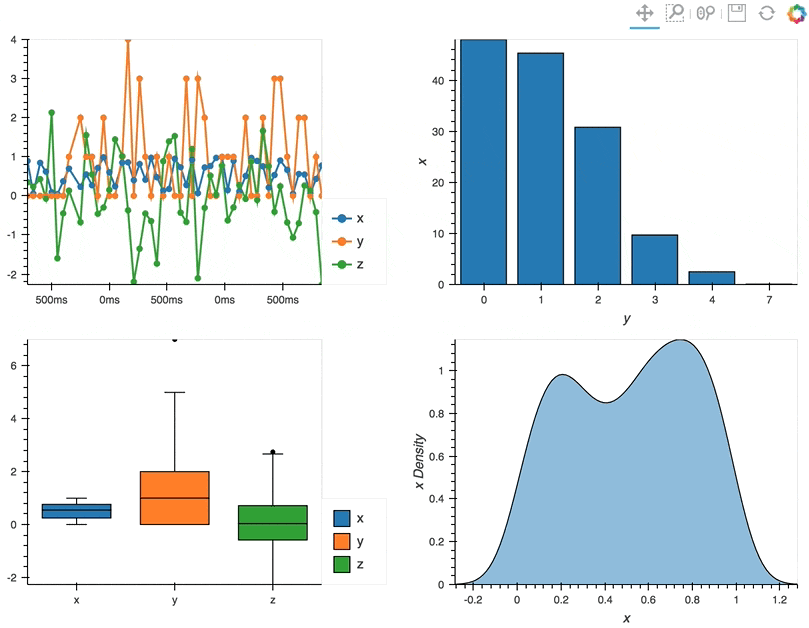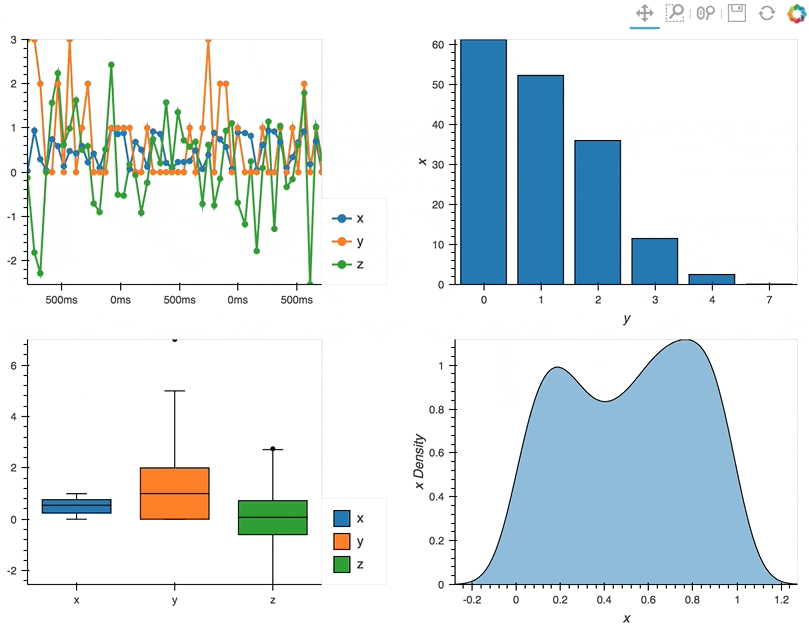
Deployment as Bokeh apps#
HoloViews objects automatically render themselves in Jupyter notebook cells, but when deploying a bokeh app the plot has to be rendered explicitly. Deploying as a Bokeh Server app allows you to share live, dynamically updated visualizations like those for streaming data, backed by a running Python process.
The following example describes how to set up a streaming DataFrame, declare some plots, compose them, set up a callback to update the plot and finally convert the composite plot to a bokeh Document, which can be served from a script using bokeh serve on the commandline.
import numpy as np
import pandas as pd
import hvplot.streamz
import holoviews as hv
from streamz import Stream
from streamz.dataframe import DataFrame
renderer = hv.renderer('bokeh')
# Set up streaming DataFrame
stream = Stream()
index = pd.DatetimeIndex([])
example = pd.DataFrame({'x': [], 'y': [], 'z': []},
columns=['x', 'y', 'z'], index=[])
df = DataFrame(stream, example=example)
cumulative = df.cumsum()[['x', 'z']]
# Declare plots
line = cumulative.hvplot.line(width=400)
scatter = cumulative.hvplot.scatter(width=400)
bars = df.groupby('y').sum().hvplot.bar(width=400)
box = df.hvplot.box(width=400)
kde = df.x.hvplot.kde(width=400)
# Compose plots
layout = (line * scatter + bars + box + kde).cols(2)
# Set up callback with streaming data
def emit():
now = pd.datetime.now()
delta = np.timedelta64(500, 'ms')
index = pd.date_range(np.datetime64(now)-delta, now, freq='100ms')
df = pd.DataFrame({'x': np.random.randn(len(index)),
'y': np.random.randint(0, 10, len(index)),
'z': np.random.randn(len(index))},
columns=['x', 'y', 'z'], index=index)
stream.emit(df)
# Render layout to bokeh server Document and attach callback
doc = renderer.server_doc(layout)
doc.title = 'Streamz HoloViews based Plotting API Bokeh App Demo'
doc.add_periodic_callback(emit, 500)
For more details on deploying Bokeh apps see the HoloViews User Guide.
Using HoloViews directly#
HoloViews itself includes first class support for streamz DataFrame and Series; for more details see the Streaming Data section in the HoloViews documentation.